Topological measures and maps of the Web
In this project we study the relationships between different
types of Web topology based for example on hyperlinks,
words, and page meaning, and how they affect the performance of
ranking and crawling algorithms, such as InfoSpiders.
This research extends prior work (see
dissertation)
in which we characterized a necessary condition
for effective autonomous browsing of any distributed hypertext
database such as the Web in terms of a relevance autocorrelation measure.
More recently we have used a brute force approach to map the
relationships between lexical, linkage, and semantic similarity
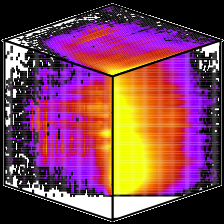
across billions of Web page pairs. The data cube in the picture
is a graphical representation of the distribution of page pairs
along the three similarity dimensions. By clicking on a face of
the cube you will see a more detailed histogram map projected
onto two similarity axes.
This research is being applied to build models that may help
understand how the scale-free distribution of Web links has emerged and
how it can be exploited for designing more effective
Web crawlers and search engines.
Collaborators
Papers
This material is based upon work supported by the National Science
Foundation under grant No. IIS-0133124/0348940. Any opinions, findings,
and conclusions or recommendations expressed in this material are
those of the author(s) and do not necessarily reflect the views of
the National Science Foundation.